ScrapBook을 사용하여 Firefox에서 전체 웹 사이트 다운로드
오프라인으로 볼 수 있도록 웹 페이지 또는 웹 사이트를 저장해야합니다.? 오랜 시간 동안 오프라인 상태가 되겠지만 즐겨 찾는 웹 사이트를 탐색 할 수 있기를 원하십니까? Firefox를 사용하는 경우 문제를 해결할 수있는 Firefox 추가 기능이 하나 있습니다..
스크랩북 당신이 웹 페이지를 저장하고 관리하기 쉬운 방법으로 그들을 구성하는 데 도움이 멋진 파이어 폭스 확장 기능입니다. 이 부가 기능에 대한 정말 멋진 점은 매우 가볍고 빠르며 정확하게 웹 페이지의 로컬 복사본을 거의 완벽하게 캐시하고 여러 언어를 지원한다는 것입니다. 나는 많은 그래픽과 멋진 CSS 스타일을 가진 여러 웹 페이지에서 그것을 테스트했고 놀랍게도 오프라인 버전이 온라인 버전과 완전히 똑같은 것을 보아서 기뻤다..

스크랩북은 다음과 같은 목적으로 사용할 수 있습니다.
- 단일 웹 페이지 저장
- 단일 웹 페이지의 일부분 또는 미리보기 저장
- 전체 웹 사이트 저장
- 폴더, 하위 폴더가있는 책갈피와 동일한 방식으로 모음 구성
- 전체 텍스트 검색 및 전체 컬렉션의 빠른 필터링 검색
- 수집 된 웹 페이지 편집
- 오페라 노트와 유사한 텍스트 / HTML 편집 기능
스크랩북 설치
이 글을 쓰고있는 시점에 v33이라는 최신 버전의 Firefox를 실행하고 있다면 ScrapBook을 올바르게 사용할 수 있도록 일부 설정을 조정해야합니다. 기본적으로 스크랩북 아이콘은 아무 데나 나타나지 않으므로 웹 페이지를 마우스 오른쪽 버튼으로 클릭하면 사용할 수있는 유일한 방법입니다. 도구 모음의 아무 곳이나 마우스 오른쪽 버튼으로 클릭하여 도구 모음 또는 메뉴에 단추를 추가하십시오. 사용자 정의.

사용자 화 화면에서 왼쪽에 ScrapBook 아이콘이 표시됩니다. 어서 도구 모음의 상단이나 메뉴로 드래그하십시오. 그런 다음 맞춤 설정 종료 단추.

스크랩북을 사용하여 웹 사이트를 저장하기 전에 추가 기능의 설정을 변경하고자 할 수 있습니다. 오른쪽 상단의 메뉴 버튼 (세 개의 수평선)을 클릭 한 다음을 클릭하면됩니다. 부가 기능.

이제 클릭하십시오. 확장 기능 그런 다음 옵션 스크랩북 부가 기능 옆에있는 버튼.

여기서 키보드 단축키, 데이터가 저장된 위치 및 기타 사소한 설정을 변경할 수 있습니다.

스크랩북을 사용하여 사이트 다운로드
이제 프로그램을 실제로 사용하는 방법에 대해 자세히 살펴 보겠습니다. 먼저 웹 페이지를 다운로드 할 웹 사이트를로드하십시오. 다운로드를 시작하는 가장 쉬운 방법은 페이지의 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 페이지 저장 또는 페이지를 다른 이름으로 저장 메뉴 하단으로 이 두 옵션은 ScrapBook에 의해 추가됩니다..

페이지 저장을 사용하면 폴더를 선택한 다음 현재 페이지 만 자동으로 저장할 수 있습니다. 일반적으로 더 많은 옵션을 원할 경우 다른 이름으로 페이지 저장 옵션을 클릭하십시오. 원하는 옵션을 선택하여 선택할 수있는 또 다른 대화 상자가 나타납니다..

중요한 섹션은 옵션, 링크 된 파일 다운로드 섹션을 클릭 한 다음 심층 저장 옵션. 기본적으로 ScrapBook은 이미지와 스타일을 다운로드하지만, 웹 사이트에서 제대로 작동하려면 JavaScript를 추가 할 수 있습니다.
링크 된 파일 다운로드 섹션에서는 링크 된 이미지를 다운로드 할뿐 아니라 사운드, 동영상 파일, 아카이브 파일을 다운로드하거나 다운로드 할 정확한 파일 형식을 지정할 수도 있습니다. 이것은 특정 형식의 파일 (Word 문서, PDF 등)에 대한 링크가 많은 웹 사이트에서 관련 파일을 모두 빠르게 다운로드하려는 경우에 매우 유용한 옵션입니다.
마지막으로, 심층 저장 옵션은 웹 사이트의 더 많은 부분을 다운로드하는 방법입니다. 기본적으로 0으로 설정되어있어 사이트의 다른 페이지 또는 다른 링크에 대한 링크를 따라 가지 않습니다. 하나를 선택하면 현재 페이지와 해당 페이지에서 링크 된 모든 것을 다운로드합니다. 현재 페이지, 첫 번째 연결된 페이지 및 첫 번째 연결된 페이지의 모든 링크에서 2의 깊이가 다운로드됩니다..
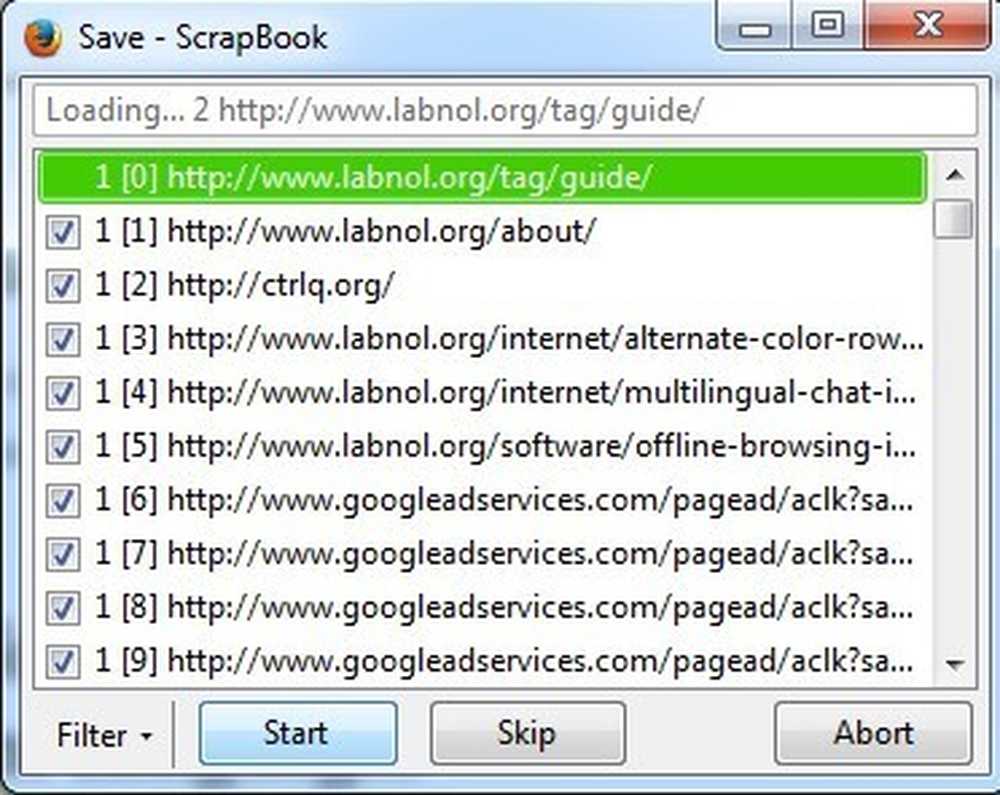
저장 버튼을 클릭하면 새 창이 열리고 페이지가 다운로드되기 시작합니다. 당신은 중지 버튼을 누르십시오. 스크랩북을 실행 시키면 다른 사이트 또는 광고 네트워크에 링크 될 수있는 소스 코드의 모든 내용을 포함하여 페이지의 모든 것을 다운로드하기 시작합니다. 위 이미지 (메인 사이트 (labnol.org) 외부)에서 볼 수 있듯이 googleadservices.com 및 ctrlq.org의 광고를 다운로드하고 있습니다..
광고를 오프라인에서 탐색하는 동안 사이트에 광고가 실제로 표시되기를 원하십니까? 이렇게하면 많은 시간과 대역폭을 낭비하게되므로 가장 좋은 방법은 일시 중지를 누른 다음 필터 단추.

가장 좋은 두 가지 옵션은 다음과 같습니다. 도메인으로 제한 과 디렉토리로 제한. 일반적으로 이들은 동일하지만 특정 사이트에서는 서로 다릅니다. 원하는 페이지를 정확히 알고 있다면 문자열로 필터링하고 나만의 URL을 입력 할 수도 있습니다. 이 옵션은 다른 모든 정크를 제거하고 소셜 미디어 사이트, 광고 네트워크 등이 아닌 실제 웹 사이트의 콘텐츠 만 다운로드하기 때문에 멋진 옵션입니다..
계속해서 클릭하십시오. 스타트 페이지가 다운로드되기 시작합니다. 다운로드 시간은 인터넷 연결 속도 및 다운로드하는 웹 사이트의 정확한 용량에 따라 다릅니다. 부가 기능은 대부분의 사이트에서 잘 작동하며 내가 만난 유일한 문제는 일부 사이트에서 자신의 콘텐츠에 연결하는 데 사용하는 URL이 절대 URL.
절대 URL 문제는 오프라인에서 Firefox에서 색인 페이지를 열고 링크를 클릭하려고하면 로컬 캐시가 아닌 실제 웹 사이트에서로드하려고 시도한다는 것입니다. 이 경우 수동으로 다운로드 디렉토리를 열고 페이지를 열어야합니다. 그것은 고통이며, 소수의 사이트에서만 발생했습니다. 그러나 발생합니다. 툴바에서 ScrapBook 버튼을 클릭 한 다음 사이트를 마우스 오른쪽 버튼으로 클릭하고 다운로드를 선택하여 다운로드 폴더를 볼 수 있습니다. 도구들 - 파일 표시.

탐색기에서 정렬 기준 유형 그런 다음 아래로 스크롤하여 파일을 찾습니다. HTML 문서. 콘텐츠 페이지는 일반적으로 index_00x 파일이 아닌 default_00x 파일입니다..

Firefox를 사용하지 않고 웹 페이지를 컴퓨터에 다운로드하려는 경우, WinHTTrack그러면 나중에 오프라인으로 탐색 할 수 있도록 전체 웹 사이트가 자동으로 다운로드됩니다. 그러나 WinHTTrack은 충분한 양의 공간을 사용하므로 하드 드라이브에 충분한 여유 공간이 있는지 확인하십시오.
두 프로그램 모두 전체 웹 사이트를 다운로드하거나 단일 웹 페이지를 다운로드하는 데 적합합니다. 실제로, 전체 웹 사이트를 다운로드하는 것은 WordPress와 같은 CMS 소프트웨어에 의해 생성되는 엄청난 수의 링크 때문에 거의 불가능합니다. 질문이 있으면 의견을 게시하십시오. 즐겨!